Genetic Algorithm (GA) is a set of algorithms inspired by the process of natural selection. They mimic the evolutionary process to find best solutions to complex problems. I always found genetic algorithms to be interesting for many tasks. However, they aren’t always a good solution to all the problems; for example, problems where A-star algorithm can be better suited.
In this post, I will demonstrate how you can use genetic algorithm to form meaningful sentences from a raw set of words. See this GitHub repo for complete code.
The Core Idea of Genetic Algorithms
Genetic Algorithms belong to the broader class of Evolutionary Algorithms (EAs) and are popular in cases where the search space is large, complex, or poorly understood.
In most nature-based algorithms, the core steps often include generation of random solutions, and selecting ones which are accidentally found to be better. We then continue refining those better solutions by applying different processes such as randomizing them, combining them, or narrowing down the search space. We then repeating the process.
Genetic algorithm is same. It involves producing random solutions, then mixing them (crossover) and slightly randomizing them again (mutation) for adding variations. And culling/removing worst solutions and continuing the process with the best ones in each generation/cycle.
Key Concepts in Genetic Algorithms
- Population: A set of possible solutions (called “individuals” or “chromosomes”) to the problem. In the algorithm, thousands of possible solutions are generated randomly or as a result of crossover or mutation.
- Chromosome: A single solution, often represented by a binary string, array, or any other suitable format depending on the problem. In our sentence construction problem, a generated sentence is a solution or chromosome.
- Genes: The smallest units in a chromosome, each representing a characteristic or a part of the solution. In our sentence construction problem, a single word is a gene. We re-combine these words/genes to form sentences/chromosomes.
- Fitness Function: A function that evaluates how “fit” or “good” each solution is in relation to the desired outcome. In our case, it will be how much our generated sentence is grammatically correct.
- Selection: The process of choosing the fittest individuals for reproduction. Usually the fitter individuals are selected.
- Crossover (Recombination): A process to combine two individuals to produce new offspring. In our case, it will be mixing of some words from one sentences and some words from another sentence, thus mixing them to make a new sequence of words (chromosome, sequence of genes).
- Mutation: A random change in a gene within a chromosome to introduce diversity. For example, replacing a word with any random word in our sentences.
Genetic Algorithm Process
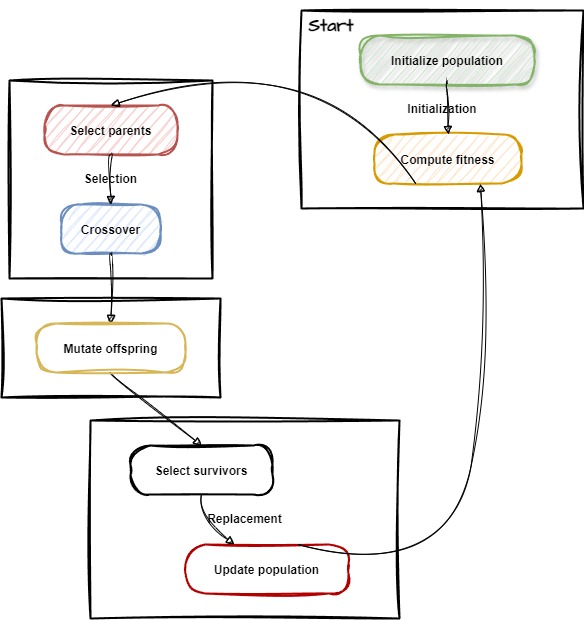
- Initialization: Generate an initial population of possible solutions, often randomly.
- Compute Fitness: Use the fitness function to evaluate each individual’s “fitness.”
- Selection: Choose the fittest individuals based on their fitness scores for reproduction.
- Crossover: Pair selected individuals to produce offspring by recombining their genes.
- Mutation: Apply random mutations to the offspring to introduce diversity.
- Replacement: Form a new generation by replacing some or all of the population with new offspring.
- Termination: Repeat the process until a termination condition is met.
Implementing Genetic Algorithm in Python
We will do sentence construction using genetic algorithm using Python. In our problem, we have several words given by the user & we have to arrange them in a way so it forms meaningful sentence. Following is the overall process that we will follow:
- First, the user enters a list of words
random_words. These words look like this in code:["is", "a", "person", "good", "he"]. - We pass these words to genetic algorithm function to generate the best sentence:
best_sentence = genetic_algorithm(random_words). - In the
genetic_algorithm()function, we do following:- Make a population of individuals, each with random sequence of words from the given set of words.
- Loop over the population, and in each generation, we:
- Calculate
fitnessof individual solutions by string comparison with the correct sentences from our dataset (a file with huge text). - Select better individuals from the population based on the calculated fitness. So the ones with most fitness value will be selected.
- These selected individuals are parents. Crossover them to produce new child solutions. In our problem, I just took half words from one parent and other half words from another parent & joined them to form a new solution.
- After children solutions are created, I just mutate them. Mutation is done by swapping a word between two randomly selected indices in the individual.
- We then add these children to population & repeat the loop.
- Calculate
Full Sentence Construction Program Code in Python
In following code, tmp.txt is the corpus file containing our text that we want to compare against for fitness.
# python program to construct a valid sentence from a list of random words
# it uses a text file as a corpus to compare the fitness of the sentence
# with the corpus and uses genetic algorithm to find the best sentence
# as we increase the corpus size, the program gets extremely slow
import random
import re
# read the large text file to be used for fitness comparison
with open('tmp.txt', 'r') as file: # text.txt is large so takes too much time for string comparison, thus using smaller tmp.txt for testing
corpus = file.read().lower()
# clean and tokenize the corpus
corpus_words = re.findall(r'\b\w+\b', corpus)
# generate a random initial population
def generate_population(words, population_size):
return [random.sample(words, len(words)) for _ in range(population_size)]
# fitness function to compare the sequence against the corpus
def fitness(sequence):
sequence_str = ' '.join(sequence)
return sum(1 for i in range(len(corpus_words) - len(sequence))
if corpus_words[i:i+len(sequence)] == sequence)
# selection: choose parents based on fitness
def select_parents(population, fitnesses):
# ensure all fitnesses are greater than zero
min_fitness = 0.1
adjusted_fitnesses = [fit + min_fitness for fit in fitnesses]
parents = random.choices(population, weights=adjusted_fitnesses, k=len(population)//2)
return parents
# crossover: create children by combining two parents
def crossover(parent1, parent2):
idx = random.randint(1, len(parent1) - 2)
child1 = parent1[:idx] + parent2[idx:]
child2 = parent2[:idx] + parent1[idx:]
return child1, child2
# mutation: randomly swap two words in the sequence
def mutate(sequence):
idx1, idx2 = random.sample(range(len(sequence)), 2)
sequence[idx1], sequence[idx2] = sequence[idx2], sequence[idx1]
return sequence
# genetic algorithm
def genetic_algorithm(words, population_size=100, generations=1000, mutation_rate=0.01):
population = generate_population(words, population_size)
for generation in range(generations):
print(f'Generation {generation}...', end='\r')
fitnesses = [fitness(seq) for seq in population]
# check if any sequence is perfect
if max(fitnesses) == len(words) - 1:
print(f'Perfect sequence found in generation {generation}')
break
parents = select_parents(population, fitnesses)
population = []
while len(population) < population_size:
parent1, parent2 = random.sample(parents, 2)
child1, child2 = crossover(parent1, parent2)
if random.random() < mutation_rate:
child1 = mutate(child1)
if random.random() < mutation_rate:
child2 = mutate(child2)
population.extend([child1, child2])
# return the best sequence found
best_sequence = max(population, key=fitness)
return best_sequence
# list of random words
random_words = ["is", "a", "person", "good", "he"]
# run the genetic algorithm
best_sentence = genetic_algorithm(random_words)
print('Best sentence:', ' '.join(best_sentence))
Exercise for You
In summer 2024 vacations, I attempted to replicate an image using genetic algorithm. Create a genetic algorithm that reads an image, then creates many randomized images and calculates their finesses. The ones most similar to the input image are the fittest, so select them and continue in the next cycle of the algorithm. This way, our image will become closer and close tot he given image in successive iterations.
Problem 1: How would we calculate the similarity of the images? Do we need to calculate pixel-by-pixel similarity (checking if pixels at (x, y) in both images have same or near-same color value?)
Problem 2: How would we know if colors of two adjacent pixels in the two images are almost same (in one image, it is blue and in another it is another shade of blue).
Problem 3: Is there another way to check for similarity between two images?